This blog post follows from the previous post on the Kalman filter and ensemble Kalman filter.
Setup
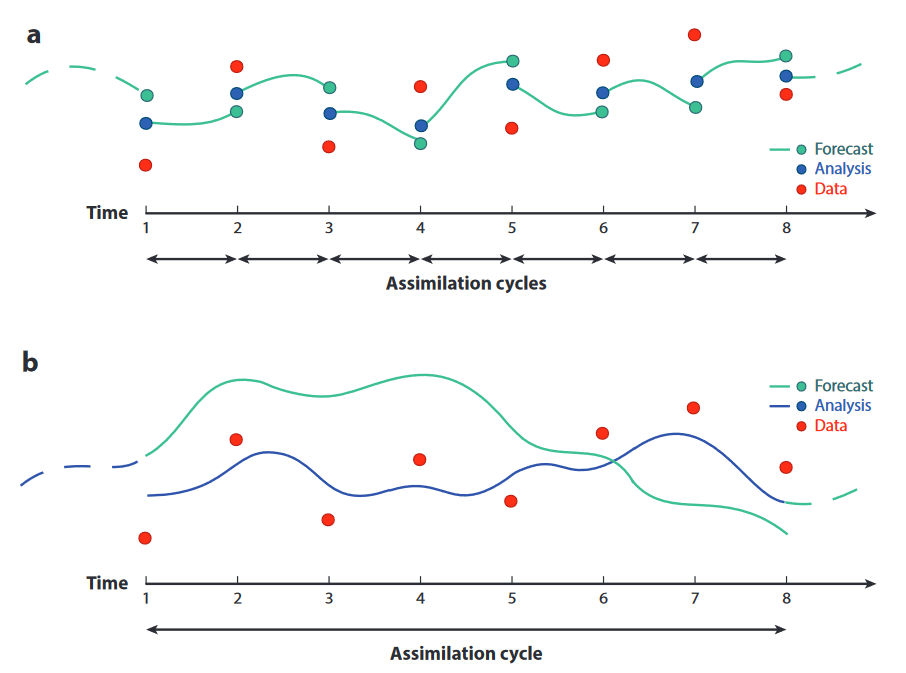
Recall from before that we consider a hidden Markov model structure with linear Gaussian conditions, and use that to establish the formulas for Kalman filter and ensemble Kalman filter.
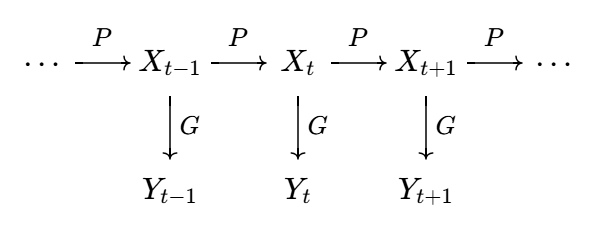
In particular, we were working with the setup of
\[ \begin{split} X_t &= \Phi X_{t-1} + \eta, \qquad \eta \sim N(0, B) \\ Y_t &= H X_t + \epsilon, \qquad \epsilon \sim N(0, R) \end{split} \]
with observation operator \(H\) being linear (i.e. can be written as a matrix). The extension to non-linear operator \(h(\cdot)\) is briefly mentioned and the extended Kalman filter method was stated.
In many practical applications of data assimilation (e.g. oceanography, meteorology), the observation operators are certainly not linear. For example, we might obtain observations about the ocean states from vessels’ measurements in the form of response amplitude operator (Nelli et al. 2023), which are non-linear operators.
The extended Kalman filter’s approach is to linearise the non-linear operator using the Jacobian at the point. Here, we will look at an alternative set of ways of data assimilation (esp. with non-linear observation operators) - the variational approaches. This set of approaches are in contrast with the sequential approaches of Kalman filter (and friends).
3D-Var
Following the previous post, at time \(t\), our prior distribution of the hidden state \(x_t\) is assumed to be \(N(x^b, B)\) \[ p(x_t) \propto \exp \left[ - \frac{1}{2} \left( x_t - x^b \right)^T B^{-1}\left( x_t - x^b \right) \right] =: \exp[-J_b(x_t)] \] and the likelihood of observing \(y_t\) given \(x_t\) is \[ p(y_t | x_t) \propto \exp \left[ -\frac{1}{2} \left( y_t - Hx_t \right)^T R^{-1} \left( y_t - Hx_t \right) \right] =: \exp[-J_o(x_t)]. \] Using the Bayes rule, we can obtain the posterior distribution of \(x_t\) after observing \(y_t\), which is given by \[ p(x_t | y_t) \propto p(x_t) p(y_t | x_t) \propto \exp[-(J_b(x_t) + J_o(x_t))] \] where \(J_b(x_t) + J_o(x_t)\) is the negative log density of the posterior distribution of \(x_t\).
The posterior mean (also mode and median due to properties of the Gaussian distribution) can be written down explicitly as
\[
\tilde{\mu}_t = x^b + B H^T (H B H^T + R)^{-1} (y_t - H \mu_t) =: x^b + K_t (y_t - H \mu_t)
\] which can also be obtained by conducting numerical optimisation (e.g. gradient descent) to minimise \(J_b(x_t) + J_o(x_t)\) - assuming the (gradient-based) numerical optimisation gives us the exact1 answer, of course.
One important thing to notice is that we do not put any \(t\) subscripts on the prior \(N(x^b, B)\) as the covariance \(B\) is fixed while \(x^b\) may vary as we move between time. This is called the background state in oceanographic data assimilation. This is the construction of optimal interpolation (Edwards et al. 2015) method.
When we move beyond the linear \(H\) case and assume non-linear observation operator \(h\), we could still do the same thing with the gradient-based approaches and obtain the posterior mean. In this case, we would have the loss functions \[ \begin{split} J(x_t) &= J_b(x_t) + J_o(x_t) \\ J_b(x_t) &= \frac{1}{2} \left( x_t - \Phi x_{t-1} \right)^T B^{-1}\left( x_t - \Phi x_{t-1} \right) \\ J_o(x_t) &= \frac{1}{2} \left( y_t - h(x_t) \right)^T R^{-1} \left( y_t - h(x_t) \right). \end{split} \] Running the numerical optimsers at each time step will give us the filtered mean of \(x_t\). The covariance is still maintained at \(B\) by the algorithm setup. This gives us the 3D-Var method.
4D-Var
3D-Var runs the optimisation of \(J\) for every new observation, under the optimal interpolation setup with non-linear observation operator \(h\). With 4D-Var, we consider a time window and try to assimilate all the observations obtained during this time window. Using the prior-likelihood-posterior setup, we will use the same prior (background \(N(x^b, B)\)) and likelihood of all the \(K\) observations to obtain the posterior, which we then minimise its negative log density.
For time window \(t\) with observations \(y_t^k\) for \(k = 1, 2, \ldots, K\), we have \[ \begin{split} J(x_t) &= J_b(x_t) + \sum_{k=1}^K J^k_o(x^k_t) \\ J_b(x_t) &= \frac{1}{2} \left( x_t - \Phi x_{t-1} \right)^T B^{-1}\left( x_t - \Phi x_{t-1} \right) \\ J^k_o(x^k_t) &= \frac{1}{2} \left( y^k_t - h^k(x^k_t) \right)^T (R^k)^{-1} \left( y^k_t - h^k(x^k_t) \right) \end{split} \] where \(h^k\) is the observation operator for the \(k\)-th observation \(y_t^k\), \(x_t^k\) is the hidden state propagated from \(x_t\) to time \(k\), and \(R^k\) is the observation noise for the \(k\)-th observation. Notice that the above loss function is assuming the data are i.i.d., thus the loss are summed.
References
Footnotes
Standard results of gradient descent tells us, since our loss function (negative log density) is convex, convergence is guaranteed when we run the optimiser for long enough.↩︎